Topic Modelling¶
Speeches by German Parliament (Bundestag)¶
Repository: github.com/raphaelw/nlp-bundestag
Project Overview (Blackbox)¶

- An algorithm works out topics
- Topics are inspected and manually annotated
Explore Dataset¶
opendiscourse.de: Richter, F.; Koch, P.; Franke, O.; Kraus, J.; Kuruc, F.; Thiem, A.; Högerl, J.; Heine, S.; Schöps, K. (2020). Open Discourse. https://doi.org/10.7910/DVN/FIKIBO. Harvard Dataverse. V3.
Exploration: Text amount by parliamentary fraction¶

"not found" are speeches by members of government (chancellor, ministers)
Exploration: Speech lengths¶
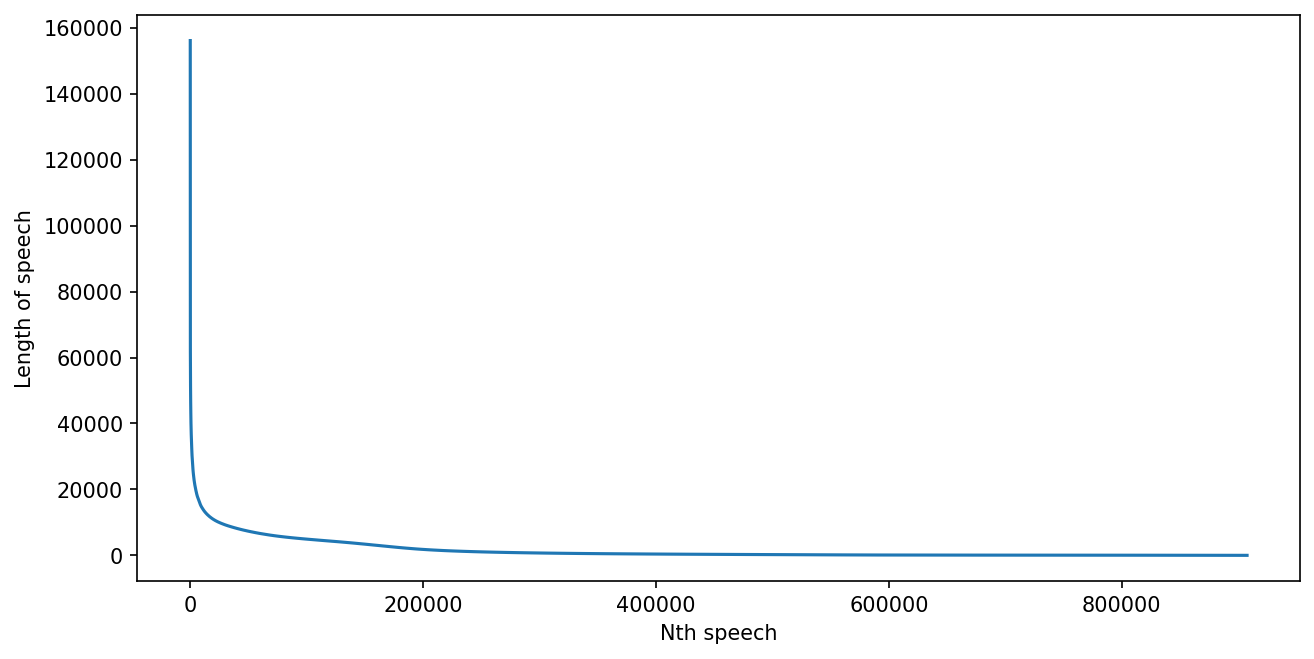
Longest speech by the first minister of finance Fritz Schäffer. December 7, 1956. PDF, Page 2.
- 160k characters, 21k Words, over 2 1/2 hours reading time (estimated).
Project Overview (Greybox)¶
- Remove stop words (the, of, and, ...)
- Generate bigrams (word pairs)
- Vectorization (bag-of-words)
- Remove rare and common words
Tech Details¶
- Number of topics specified: 50
- Computation time:
- Preprocessing: 10 hours
- LDA: 7 hours
Tech Used¶
- Hardware: Intel i7 (3rd Gen), 16 GB RAM
- Scientific Python
- JupyterLab, pandas, matplotlib
- Apache Arrow (load serialized pandas DataFrames)
- Natural Language Processing
- Visualization
Results¶
Visit: github.com/raphaelw/nlp-bundestag/blob/main/topics.md
Topic 8: German reunification (Deutsche Wiedervereinigung)¶

Topic 9: Trade agreements (Handelsabkommen)¶

Topic 16: Family policy (Familienpolitik)¶

Topic 29: Military missions (Militäreinsätze)¶

jawohl - Yes, Sir!
Topic 34: Gender equality (Gleichberechtigung)¶

Final thoughts and room for improvement¶
- Where are data protection / privacy speeches?
- LDA Parameters
- Try different number of topics
- Improve lemmatization or use stemming
- Split those long concatenated german words
- Find stop words specific to this dataset